In this post, I create the social network of a book. The idea is to create a window of words and slide this window through the text. If two characters appear in the same window of text, a link is formed among these characters. Since I analyze the same book of the previous blog post, this article may be considered a follow-up; some parts of the data-preprocessing section may coincide.
Book and dictionary selection
I’ve chosen to analyze “The Tartar Steppe” by Dino Buzzati, which is my favorite novel. The main theme of the novel is the flee of time, and it is a recommended read for everyone who is struggling with a routine. The original text is in Italian, but I was able to easily find online the English version of the book in a .txt. (LINK)
Pre-processing
Before analyzing the book, I manually removed a few lines of text from the head of the documents, since they were not related to the actual content.
The first step to analyze the book was to load the text and remove all of the unwanted characters. To do that, I selected a list of characters that I wanted to keep and I removed all of the others.
#Libraries
import spacy
nlp=spacy.load('en_core_web_sm')
from spacy.lang.en.stop_words import STOP_WORDS
import numpy as np
import matplotlib.pyplot as plt
import networkx as nx
from itertools import combinations
import pathpy as pp
import matplotlib.cm as cm
import community as community_louvain
#Load text and create a list of non-word characters and a text of only lowercase words
text = open('tartarsteppe.txt', 'r').read()
text = str.lower(text)
letters = "abcdefghijklmnopqrstuvwxyz "
non_word=text
for i in non_word:
if i in letters:
non_word = non_word.replace(i, "")
non_word=list(set(non_word))
for i in text:
if i in non_word:
text = text.replace(i, " ")
I proceed to tokenize and lemmatize the text using the spaCy library; after that, I remove all the stopwords and spaces in excess.
#Tokenize and lemmanize
my_doc = nlp(text)
token_list = []
for token in my_doc:
token_list.append(token.lemma_)
#Remove stopwords and spaces
testo = []
for word in token_list:
lexeme = nlp.vocab[word]
if lexeme.is_stop == False:
if lexeme!="-PRON-":
if len(word.strip())>1:
testo.append(word.strip())
print("The cleaned text is composed of "+str(len(testo))+" words.")
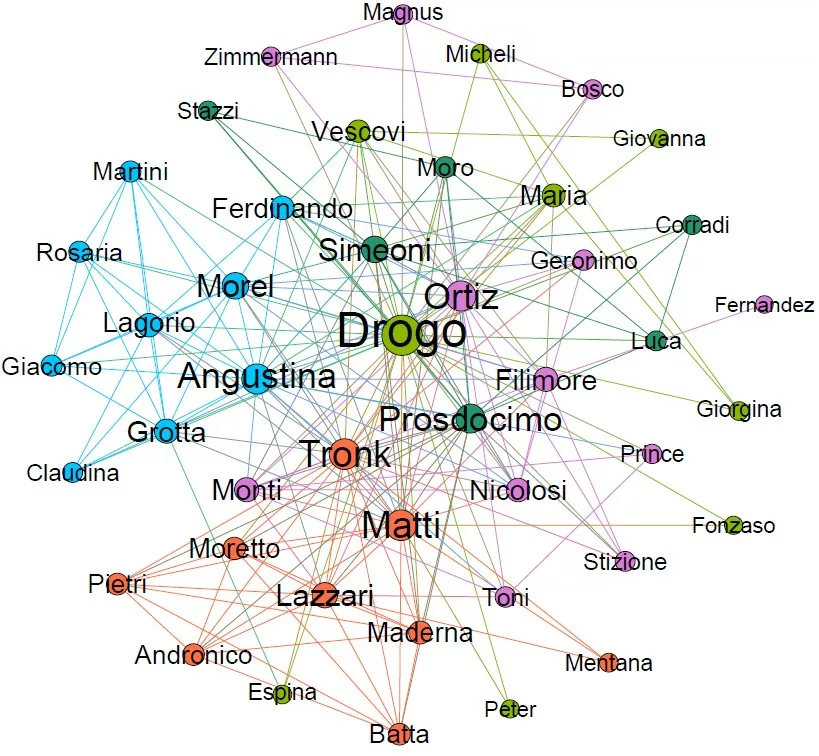
I introduce the list of characters, which are going to form the nodes of my network. Since I want to introduce all of the characters that appear and/or are mentioned at least once in the book, I cannot rely on character lists found online (otherwise I would have a network of around 10 nodes). Since the book is not very long, I manually looked for names within the sub-sample of capitalized words in the text. I then grouped all names, surnames and nicknames, obtaining a network of 48 characters.
#List of all characters that appear and/or are mentioned at least once in the book.
#For each character I put name, surname and nicknames.
characters=[['Drogo','Giovanni'],['Ortiz'],['Zimmermann'],['Vescovi','Francesco'],['Morel','Carlo'],
['Angustina','Pietro'],['Grotta','Franceseo'],['Lagorio','Max'],['Matti','Math'],
['Lazzari','Giuseppe'],['Moretto', 'Martelli'],['Prince','Sebastian'],['Nicolosi'],
['Laterio'],['Moro'],['Simeoni'],['Stazzi'],['Tronk'],['Filimore'],['Maderna'],['Monti'],
['Andronico'],['Maderna'],['Luca'],['Prosdocimo'],['Claudina'],['Maria'],['Ferdinando','Rovina'],
['Giovanna'],['Fernandez'],['Magnus'],['Giorgina'],['Mentana'],['Zimmermann'],['Bosco'],
['Martini'],['Rosaria'],['Geronimo'],['Espina'],['Stizione'],['Corradi'],['Giacomo'],
['Micheli'],['Batta'],['Toni'],['Pietri'],['Peter'],['Fonzaso']]
#First I create a dictionary that I use to map labels to node ID
labels={}
for i in range(len(characters)):
labels[i]=characters[i][0].capitalize()
#Here I create a dictionary that map a word as it appears in the book to the node ID
diz_char={}
for i in range(len(characters)):
for ii in range(len(characters[i])):
diz_char[characters[i][ii]]=i
print(len(characters))
Temporal network and communities
Now I introduce the parameters that are going to be used in my text analysis. I selected a window of 250 words that is going to slide through the text, with an overlap of 50 words.
T=250 #Text window of analysis
overlap=50 #Text overlap
N_win=round(len(testo)/(T-overlap)-0.5)+1
print("The book is divided in "+str(N_win)+" parts")
Here, I introduce the functions that are used to generate the temporal network. First, there is a function that extracts the list of nodes that are present in a text window. Then there is a function that takes as input this list of nodes and add to the network all combinations of links, if they are not already present; additionally,
this function assigns to each link a time attribute. Finally, there is a function that slides trough the text and uses the previously mentioned functions and parameters to construct the temporal network.
#Function that takes list of words and extract a list of nodes def extract_nodes(sentences,dizionario): listona=[] for i in sentences: if dizionario.get(i)!=None: listona.append(dizionario.get(i)) listona=list(set(listona)) return listona #Function that adds edges with time attribute to network if the node does not exhist. def insert_nodes(G,nodes,ttt): if len(nodes)>1: for u,v in list(combinations(nodes,2)): if G.has_edge(u,v)==False: G.add_edge(u, v, time=ttt) return G #Function that create a temporal network using the previous two functions. def network_book(testo,T,overlap=0): G=nx.Graph() N_win=round(len(testo)/(T-overlap)-0.5) for window in range(N_win+1): t_w=testo[(T-overlap)*window:(T-overlap)*window+T] if len(t_w)>0: insert_nodes(G,extract_nodes(t_w,diz_char),window) return G
After the construction of the network, I use the Louvain algorithm to detect communities in the final stage of the network.
#Create community using Louvain algorithm partition = community_louvain.best_partition(G)
Temporal Network
Representation of the temporal network, where blue links represent links that are formed at the beginning of the book, yellow links in the middle and red links at the end.
Interactive Temporal Network
Here I create an interactive visualization of how the social network of the story unfolds.
Community Network
Visualization of the different communities found using the Louvain algorithm.